



ケーブル駆動型パラレルロボットは、限られたスペースでどのように移動し、動的な障害物を回避するかが重要な課題となっている。
ハルビン工業大学(深圳)のXiong Hao氏のチームは興味深い研究を行い、「Dynamic Obstacle Avoidance for Cable-Driven Parallel Robots with Mobile Bases via Sim-to-Real Reinforcement Learning」と題する論文がSCI&EI索引付きジャーナルIEEE Robotics and Automation Lettersに掲載された。
Xiong Hao氏の研究チームは、関連する研究成果を2024 International Conference on Intelligent Robots and Systems (ICRA)で展示する予定である。

研究要旨
研究の背景
ケーブル駆動パラレルロボット(CDPR)は、剛体リンクの代わりにケーブルを使用してエンドエフェクタの位置を制御する新しいタイプのパラレルロボットである。
シンプルな構造、低慣性、広い作業領域、優れた動的性能を持つ。機器製造、医療リハビリ、航空宇宙、その他の分野での応用に非常に適している。幾何学的な構成を変更できるため、特に制約の多い環境での作業に適している。

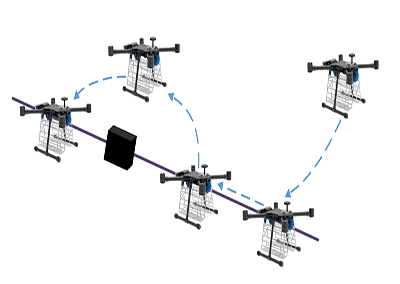
4つの可動ベースを持つロープ牽引平行ロボット
制約の多い環境では、CDPRは軌道計画手法では考慮されない動的な障害物に遭遇することがあり、障害物を迂回したり横切ったりするためのリアルタイム回避行動が必要となる。高次元の状態空間と、複数のケーブルと移動ベースから生じる制約のため、これは困難な課題である。
本研究では、CDPRが障害物を動的に回避し、衝突を回避し、必要に応じて目標軌道に戻ることを可能にするアルゴリズムを提案することで、この問題に取り組みます。

CDPRは軌道計画中に動的な障害物に遭遇する可能性がある
障害物回避アルゴリズム
本研究では、強化学習(RL)に基づく障害物回避制御器(OAC)を提案し、軌道追跡制御器(TTC)に統合する。OACの設計は、ソフト・アクター・クリティック(SAC)アルゴリズムと注意モジュールに基づいており、移動ベースに接続された固定長ケーブルを持つCPDRのリアルタイム障害物回避問題に対処する。
この手法は、CDPRの複数の制約と高次元状態空間を扱うことができ、リアルタイムの動的障害物環境における動的障害物回避を実現する。

SACアルゴリズムに基づく障害物回避コントローラ
RLベースのOACは、Mujocoシミュレータにおいて、2段階訓練と1段階訓練の2つの訓練戦略を用いて訓練された。
2段階の訓練戦略では、OACは50,000サイクル以内に収束し、訓練時間は約35分であった。シングルステージ訓練戦略では、OACは50万サイクル以内に収束し、訓練時間は約5.5時間である。どちらのOACも最終的にはほぼ同じ結果になる。この研究は、報酬シェーピング技術を利用した2段階の訓練戦略により、OACの訓練を迅速化できることを示している。
実世界での実験
学習したRLベースのOACアルゴリズムを実環境でテストした。
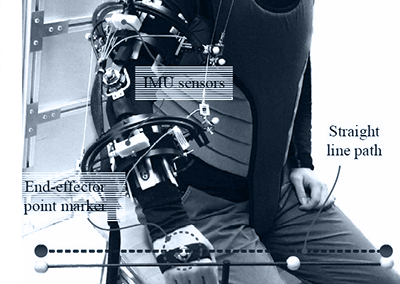
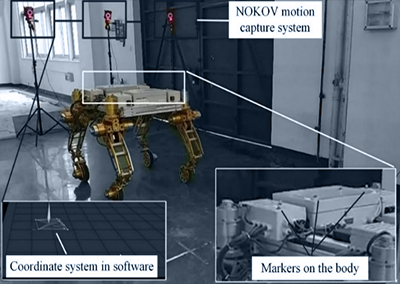
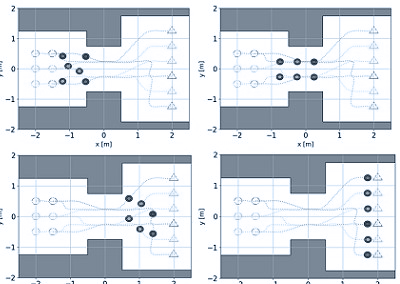
実験セットアップは、4本の移動ベースを4本の固定長ケーブルで接続したケーブル駆動パラレルロボット(CDPR)で構成した。障害物は高さ0.32mの低障害物と高さ0.92mの高障害物の2種類を使用した。
CDPRの移動プラットフォームは、高さの低い障害物を通過することができたが、衝突を避けるために高い障害物を回避する必要があった。
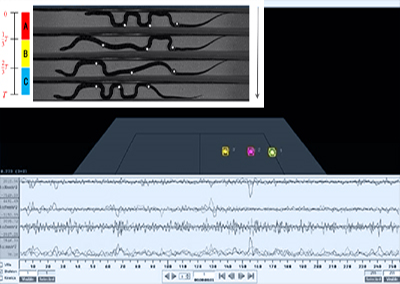
実験中、NOKOVモーションキャプチャシステムを導入し、ケーブル、移動台、動的障害物の位置と姿勢をリアルタイムにキャプチャした。

異なる高さの障害物に遭遇した際にCPDRが行った回避行動
RLベースのOAC手法は、異なる高さの障害物を乗り越えたり回避したりするために、CDPRが異なる回避戦略を採用するように誘導することに成功した。
参考文献:





















































































ここでごニーズを出ること
-
もっと多い情報に関して、メッセージをしたりしてください。
-
- 確認